
A
web crawler (also known as a
Web spider or
Web robot) is a program or automated script which browses the
World Wide Web in a methodical, automated manner. Other less frequently used names for Web crawlers are
ants,
automatic indexers,
bots, and
worms (Kobayashi and Takeda, 2000).
This process is called
Web crawling or
spidering. Many sites, in particular
search engines, use spidering as a means of providing up-to-date data. Web crawlers are mainly used to create a copy of all the visited pages for later processing by a search engine that will
index the downloaded pages to provide fast searches. Crawlers can also be used for automating maintenance tasks on a Web site, such as checking links or validating
HTML code. Also, crawlers can be used to gather specific types of information from Web pages, such as harvesting e-mail addresses (usually for
spam).
A Web crawler is one type of
bot, or software agent. In general, it starts with a list of
URLs to visit, called the
seeds. As the crawler visits these URLs, it identifies all the
hyperlinks in the page and adds them to the list of URLs to visit, called the
crawl frontier. URLs from the frontier are recursively visited according to a set of policies.
Crawling policies Given the current size of the Web, even large search engines cover only a portion of the publicly available internet; a study by
Lawrence and
Giles (Lawrence and Giles,
2000) showed that no search engine indexes more than 16% of the Web. As a crawler always downloads just a fraction of the Web pages, it is highly desirable that the downloaded fraction contains the most relevant pages, and not just a random sample of the Web.
This requires a metric of importance for prioritizing Web pages. The importance of a page is a function of its intrinsic quality, its popularity in terms of links or visits, and even of its URL (the latter is the case of vertical search engines restricted to a single top-level domain, or search engines restricted to a fixed Web site). Designing a good selection policy has an added difficulty: it must work with partial information, as the complete set of Web pages is not known during crawling.
Cho
et al. (Cho
et al.,
1998) made the first study on policies for crawling scheduling. Their data set was a 180,000-pages crawl from the
stanford.edu domain, in which a crawling simulation was done with different strategies. The ordering metrics tested were
breadth-first,
backlink-count and partial
Pagerank calculations. One of the conclusions was that if the crawler wants to download pages with high Pagerank early during the crawling process, then the partial Pagerank strategy is the better, followed by breadth-first and backlink-count. However, these results are for just a single domain.
Najork and Wiener (Najork and Wiener,
2001) performed an actual crawl on 328 million pages, using breadth-first ordering. They found that a breadth-first crawl captures pages with high Pagerank early in the crawl (but they did not compare this strategy against other strategies). The explanation given by the authors for this result is that "the most important pages have many links to them from numerous hosts, and those links will be found early, regardless of on which host or page the crawl originates".
Abiteboul (Abitebout
et al.,
2003) designed a crawling strategy based on an algorithm called OPIC (On-line Page Importance Computation). In OPIC, each page is given an initial sum of "cash" which is distributed equally among the pages it points to. It is similar to a Pagerank computation, but it is faster and is only done in one step. An OPIC-driven crawler downloads first the pages in the crawling frontier with higher amounts of "cash". Experiments were carried in a 100,000-pages synthetic graph with a power-law distribution of in-links. However, there was no comparison with other strategies nor experiments in the real Web.
Boldi
et al. (Boldi
et al.,
2004) used simulation on subsets of the Web of 40 million pages from the
.it domain and 100 million pages from the WebBase crawl, testing breadth-first against depth-first, random ordering and an omniscient strategy. The comparison was based on how well PageRank computed on a partial crawl approximates the true PageRank value. Surprisingly, some visits that accumulate PageRank very quickly (most notably, breadth-first and the omniscent visit) provide very poor progressive approximations.
Baeza-Yates
et al. (Baeza-Yates
et al.,
2005) used simulation on two subsets of the Web of 3 million pages from the
.gr and
.cl domain, testing several crawling strategies. They showed that both the OPIC strategy and a strategy that uses the length of the per-site queues are both better than breadth-first crawling, and that it is also very effective to use a previous crawl, when it is available, to guide the current one.
Selection policy A crawler may only want to seek out HTML pages and avoid all other
MIME types. In order to request only HTML resources, a crawler may make an HTTP HEAD request to determine a Web resource's MIME type before requesting the entire resource with a GET request. To avoid making numerous HEAD requests, a crawler may alternatively examine the URL and only request the resource if the URL ends with .html, .htm or a slash. This strategy may cause numerous HTML Web resources to be unintentionally skipped. A similar strategy compares the extension of the web resource to a list of known HTML-page types: .html, .htm, .asp, .aspx, .php, and a slash.
Some crawlers may also avoid requesting any resources that have a
"?" in them (are dynamically produced) in order to avoid
spider traps which may cause the crawler to download an infinite number of URLs from a Web site.
Restricting followed links Some crawlers intend to download as many resources as possible from a particular Web site. Cothey (Cothey, 2004) introduced a
path-ascending crawler that would ascend to every path in each URL that it intends to crawl. For example, when given a seed URL of http://llama.org/hamster/monkey/page.html, it will attempt to crawl /hamster/monkey/, /hamster/, and /. Cothey found that a path-ascending crawler was very effective in finding isolated resources, or resources for which no inbound link would have been found in regular crawling.
Many Path-ascending crawlers are also known as
Harvester software, because they're used to "harvest" or collect all the content - perhaps the collection of photos in a gallery - from a specific page or host.
Path-ascending crawling Main article: Focused crawler Focused crawling A vast amount of Web pages lie in the
deep or invisible Web. These pages are typically only accessible by submitting queries to a database, and regular crawlers are unable to find these pages if there are no links that point to them. Google's
Sitemap Protocol and
mod oai (Nelson
et al., 2005) are intended to allow discovery of these deep-Web resources.
Crawling the Deep Web The Web has a very dynamic nature, and crawling a fraction of the Web can take a really long time, usually measured in weeks or months. By the time a Web crawler has finished its crawl, many events could have happened. These events can include creations, updates and deletions.
From the search engine's point of view, there is a cost associated with not detecting an event, and thus having an outdated copy of a resource. The most used cost functions, introduced in (Cho and Garcia-Molina, 2000), are freshness and age.
Freshness: This is a binary measure that indicates whether the local copy is accurate or not. The freshness of a page
p in the repository at time
t is defined as:
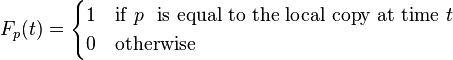 Age
Age: This is a measure that indicates how outdated the local copy is. The age of a page
p in the repository, at time
t is defined as:
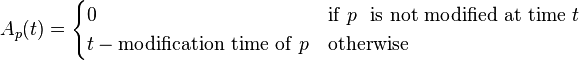
Coffman
et al. (Edward G. Coffman, 1998) worked with a definition of the objective of a web crawler that is equivalent to freshness, but use a different wording: they propose that a crawler must minimize the fraction of time pages remain outdated. They also noted that the problem of web crawling can be modeled as a multiple-queue, single-server polling system, on which the Web crawler is the server and the Web sites are the queues. Page modifications are the arrival of the customers, and switch-over times are the interval between page accesses to a single Web site. Under this model, mean waiting time for a customer in the polling system is equivalent to the average age for the Web crawler.
The objective of the crawler is to keep the average freshness of pages in its collection as high as possible, or to keep the average age of pages as low as possible. These objectives are not equivalent: in the first case, the crawler is just concerned with how many pages are out-dated, while in the second case, the crawler is concerned with how old the local copies of pages are.
Two simple re-visiting policies were studied by Cho and Garcia-Molina (Cho and Garcia-Molina, 2003):
Uniform policy: This involves re-visiting all pages in the collection with the same frequency, regardless of their rates of change.
Proportional policy: This involves re-visiting more often the pages that change more frequently. The visiting frequency is directly proportional to the (estimated) change frequency.
(In both cases, the repeated crawling order of pages can be done either at random or with a fixed order.)
Cho and Garcia-Molina proved the surprising result that, in terms of average freshness, the uniform policy outperforms the proportional policy in both a simulated Web and a real Web crawl. The explanation for this result comes from the fact that, when a page changes too often, the crawler will waste time by trying to re-crawl it too fast and still will not be able to keep its copy of the page fresh.
To improve freshness, we should penalize the elements that change too often (Cho and Garcia-Molina, 2003a). The optimal re-visiting policy is neither the uniform policy nor the proportional policy. The optimal method for keeping average freshness high includes ignoring the pages that change too often, and the optimal for keeping average age low is to use access frequencies that monotonically (and sub-linearly) increase with the rate of change of each page. In both cases, the optimal is closer to the uniform policy than to the proportional policy: as Coffman
et al. (Edward G. Coffman, 1998) note, "in order to minimize the expected obsolescence time, the accesses to any particular page should be kept as evenly spaced as possible". Explicit formulas for the re-visit policy are not attainable in general, but they are obtained numerically, as they depend on the distribution of page changes. (Cho and Garcia-Molina, 2003a) show that the exponential distribution is a good fit for describing page changes, while (Ipeirotis
et al., 2005) show how to use statistical tools to discover parameters that affect this distribution. Note that the re-visiting policies considered here regard all pages as homogeneous in terms of quality ("all pages on the Web are worth the same"), something that is not a realistic scenario, so further information about the Web page quality should be included to achieve a better crawling policy.
Re-visit policy Crawlers can retrieve data much quicker and in greater depth than human searchers, so they can have a crippling impact on the performance of a site. Needless to say if a single crawler is performing multiple requests per second and/or downloading large files, a server would have a hard time keeping up with requests from multiple crawlers.
As noted by Koster (Koster, 1995), the use of Web crawlers is useful for a number of tasks, but comes with a price for the general community. The costs of using Web crawlers include:
A partial solution to these problems is the
robots exclusion protocol, also known as the robots.txt protocol (Koster, 1996) that is a standard for administrators to indicate which parts of their Web servers should not be accessed by crawlers. This standard does not include a suggestion for the interval of visits to the same server, even though this interval is the most effective way of avoiding server overload. Recently commercial search engines like
Ask Jeeves,
MSN and
Yahoo are able to use an extra "Crawl-delay:" parameter in the robots.txt file to indicate the number of seconds to delay between requests.
The first proposal for the interval between connections was given in (Koster, 1993) and was 60 seconds. However, if pages were downloaded at this rate from a website with more than 100,000 pages over a perfect connection with zero latency and infinite bandwidth, it would take more than 2 months to download only that entire website; also, only a fraction of the resources from that Web server would be used. This does not seem acceptable.
Cho (Cho and Garcia-Molina, 2003) uses 10 seconds as an interval for accesses, and the WIRE crawler (Baeza-Yates and Castillo, 2002) uses 15 seconds as the default. The MercatorWeb crawler (Heydon and Najork, 1999) follows an adaptive politeness policy: if it took
t seconds to download a document from a given server, the crawler waits for 10
t seconds before downloading the next page. Dill
et al. (Dill
et al., 2002) use 1 second.
Anecdotal evidence from access logs shows that access intervals from known crawlers vary between 20 seconds and 3–4 minutes. It is worth noticing that even when being very polite, and taking all the safeguards to avoid overloading Web servers, some complaints from Web server administrators are received.
Brin and
Page note that: "... running a crawler which connects to more than half a million servers (...) generates a fair amount of email and phone calls. Because of the vast number of people coming on line, there are always those who do not know what a crawler is, because this is the first one they have seen." (Brin and Page, 1998).
Network resources, as crawlers require considerable bandwidth and operate with a high degree of parallelism during a long period of time.
Server overload, especially if the frequency of accesses to a given server is too high.
Poorly written crawlers, which can crash servers or routers, or which download pages they cannot handle.
Personal crawlers that, if deployed by too many users, can disrupt networks and Web servers.
Politeness policy Main article: Distributed web crawling Parallelization policy A crawler must not only have a good crawling strategy, as noted in the previous sections, but it should also have a highly optimized architecture.
Shkapenyuk and Suel (Shkapenyuk and Suel, 2002) noted that: "While it is fairly easy to build a slow crawler that downloads a few pages per second for a short period of time, building a high-performance system that can download hundreds of millions of pages over several weeks presents a number of challenges in system design, I/O and network efficiency, and robustness and manageability."
Web crawlers are a central part of search engines, and details on their algorithms and architecture are kept as business secrets. When crawler designs are published, there is often an important lack of detail that prevents others from reproducing the work. There are also emerging concerns about "
search engine spamming", which prevent major search engines from publishing their ranking algorithms.
URL normalization Web crawlers typically identify themselves to a Web server by using the
User-agent field of an
HTTP request. Web site administrators typically examine their
web servers' log and use the user agent field to determine which crawlers have visited the Web server and how often. The user agent field may include a
URL where the Web site administrator may find out more information about the crawler.
Spambots and other malicious Web crawlers are unlikely to place identifying information in the user agent field, or they may mask their identity as a browser or other well-known crawler.
It is important for Web crawlers to identify themselves so Web site administrators can contact the owner if needed. In some cases, crawlers may be accidentally trapped in a
crawler trap or they may be overloading a Web server with requests, and the owner needs to stop the crawler. Identification is also useful for administrators that are interested in knowing when they may expect their Web pages to be indexed by a particular
search engine.
Crawler identification The following is a list of published crawler architectures for general-purpose crawlers (excluding focused Web crawlers), with a brief description that includes the names given to the different components and outstanding features:
RBSE (Eichmann, 1994) was the first published web crawler. It was based on two programs: the first program, "
spider" maintains a queue in a relational database, and the second program "
mite", is a modified
www ASCII browser that downloads the pages from the Web.
WebCrawler (Pinkerton, 1994) was used to build the first publicly-available full-text index of a subset of the Web. It was based on lib-WWW to download pages, and another program to parse and order URLs for breadth-first exploration of the Web graph. It also included a real-time crawler that followed links based on the similarity of the anchor text with the provided query.
World Wide Web Worm (McBryan, 1994) was a crawler used to build a simple index of document titles and URLs. The index could be searched by using the
grep Unix command.
Google Crawler (Brin and Page, 1998) is described in some detail, but the reference is only about an early version of its architecture, which was based in C++ and
Python. The crawler was integrated with the indexing process, because text parsing was done for full-text indexing and also for URL extraction. There is a URL server that sends lists of URLs to be fetched by several crawling processes. During parsing, the URLs found were passed to a URL server that checked if the URL have been previously seen. If not, the URL was added to the queue of the URL server.
CobWeb (da Silva
et al., 1999) uses a central "scheduler" and a series of distributed "collectors". The collectors parse the downloaded Web pages and send the discovered URLs to the scheduler, which in turn assign them to the collectors. The scheduler enforces a breadth-first search order with a politeness policy to avoid overloading Web servers. The crawler is written in
Perl.
Mercator (Heydon and Najork, 1999; Najork and Heydon, 2001) is a distributed, modular web crawler written in
Java. Its modularity arises from the usage of interchangeable "protocol modules" and "processing modules". Protocols modules are related to how to acquire the Web pages (e.g.: by
HTTP), and processing modules are related to how to process Web pages. The standard processing module just parses the pages and extract new URLs, but other processing modules can be used to index the text of the pages, or to gather statistics from the Web.
WebFountain (Edwards
et al., 2001) is a distributed, modular crawler similar to Mercator but written in C++. It features a "controller" machine that coordinates a series of "ant" machines. After repeatedly downloading pages, a change rate is inferred for each page and a non-linear programming method must be used to solve the equation system for maximizing freshness. The authors recommend to use this crawling order in the early stages of the crawl, and then switch to a uniform crawling order, in which all pages are being visited with the same frequency.
PolyBot [Shkapenyuk and Suel, 2002] is a distributed crawler written in C++ and Python, which is composed of a "crawl manager", one or more "downloaders" and one or more "DNS resolvers". Collected URLs are added to a queue on disk, and processed later to search for seen URLs in batch mode. The politeness policy considers both third and second level domains (e.g.: www.example.com and www2.example.com are third level domains) because third level domains are usually hosted by the same Web server.
WebRACE (Zeinalipour-Yazti and Dikaiakos, 2002) is a crawling and caching module implemented in Java, and used as a part of a more generic system called eRACE. The system receives requests from users for downloading Web pages, so the crawler acts in part as a smart proxy server. The system also handles requests for "subscriptions" to Web pages that must be monitored: when the pages change, they must be downloaded by the crawler and the subscriber must be notified. The most outstanding feature of WebRACE is that, while most crawlers start with a set of "seed" URLs, WebRACE is continuously receiving new starting URLs to crawl from.
Ubicrawler (Boldi
et al., 2004) is a distributed crawler written in Java, and it has no central process. It is composed of a number of identical "agents"; and the assignment function is calculated using consistent hashing of the host names. There is zero overlap, meaning that no page is crawled twice, unless a crawling agent crashes (then, another agent must re-crawl the pages from the failing agent). The crawler is designed to achieve high scalability and to be tolerant to failures.
FAST Crawler (Risvik and Michelsen, 2002) is the crawler used by the FAST search engine, and a general description of its architecture is available. It is a distributed architecture in which each machine holds a "document scheduler" that maintains a queue of documents to be downloaded by a "document processor" that stores them in a local storage subsystem. Each crawler communicates with the other crawlers via a "distributor" module that exchanges hyperlink information.
Labrador is a closed-source web crawler that works with the Open Source project
Terrier search engine
Spinn3r Is a crawler used to build
Tailrank. Spinn3r is based on Java and the majority of it's architecture is Open Source. Spinn3r is mostly oriented around crawling the blogosphere.
In addition to the specific crawler architectures listed above, there are general crawler architectures published by Cho (Cho and Garcia-Molina, 2002) and Chakrabarti (Chakrabarti, 2003).
HotCrawler HotCrawler is a crawler written in C, and PHP. HotCrawler crawls websites by visiting a list of URLs listed in it's database, and it adds new URLs to it's queue as it find them, and it's separated from the search engine. If the URL is already crawled through the queue session, it adds it to the last queue session created. It's kind of two separated programs, a one that downloads pages and saves copies of it in a database, and another program that determine the next time to visit a page, based on many factors.
Open-source crawlers Distributed web crawling Focused crawler Internet Archive Library of Congress Digital Library project National Digital Information Infrastructure and Preservation Program PageRank Spambot Spider trap Spidering Hacks - an O'Reilly book focused on spider-like programming
Search Engine Indexing - the step after crawling
Web archiving
No comments:
Post a Comment